"XX 發(fā)布最強開源大模型,多項基準測試全面超越 XX 等閉源模型!"
" 萬億參數(shù)開源模型 XX 強勢登頂全球開源模型榜首!"
" 國產(chǎn)之光!XX 模型在中文評測榜單拿下第一!"
隨著 AI 時代的到來,各位的朋友圈、微博等社交平臺是不是也常常被諸如此類的新聞刷屏了?
今天這個模型拿到了冠軍,明天那個模型變成了王者。評論區(qū)里有的人熱血沸騰,有的人一頭霧水。
一個又一個的現(xiàn)實問題擺在眼前:
這些模型所謂的 " 登頂 " 比的是什么?誰給它們評分,而評分的依據(jù)又是什么?為什么每個平臺的榜單座次都不一樣,到底誰更權威?
如果各位也產(chǎn)生了類似的困惑,說明各位已經(jīng)開始從 " 看熱鬧 " 轉向 " 看門道 "。
本文之中,我們便來拆解一下不同類型 "AI 競技場 " ——也就是大語言模型排行榜——的 " 游戲規(guī)則 "。
01 類型一:客觀基準測試(Benchmark),給 AI 準備的 " 高考 "
人類社會中,高考分數(shù)是決定學生大學檔次的最主要評判標準。
同樣地,在 AI 領域,也有很多高度標準化的測試題,用來盡可能客觀地衡量 AI 模型在特定能力上的表現(xiàn)。
因此,在這個大模型產(chǎn)品頻繁推陳出新的時代,各家廠商推出新模型后,第一件事就是拿到 " 高考 " 考場上跑個分,是騾子是馬,拉出來遛遛。
Artificial Analysis 平臺提出了一項名為 "Artificial Analysis Intelligence Index(AAII)" 的綜合性評測基準,匯總了 7 個極為困難且專注于前沿能力的單項評測結果。
類似于股票價格指數(shù),AAII 能夠給出衡量 AI 智能水平的綜合分數(shù),尤其專注于需要深度推理、專業(yè)知識和復雜問題解決能力的任務。
這 7 項評測覆蓋了被普遍視作衡量高級智能核心的三個領域:知識推理、數(shù)學和編程。
(1)知識與推理領域
MMLU-Pro:
全稱 Massive Multitask Language Understanding - Professional Level
MMLU 的加強版。MMLU 涵蓋 57 個學科的知識問答測試,而 MMLU-Pro 在此基礎上,通過更復雜的提問方式和推理要求,進一步增加難度以測試模型在專業(yè)領域的知識廣度和深度推理能力。
GPQA Diamond:
全稱 Graduate - Level Google - Proof Q&A - Diamond Set
此測試機包含生物學、物理學和化學領域的專業(yè)問題。與其名稱對應,其設計初衷很直白:即使是相關領域的研究生,在允許使用 Google 搜索的情況下也很難在短時間內找到答案。而 Diamond 正是其中難度最高的一個子集,需要 AI 具備較強的推理能力和問題分解能力,而非簡單的信息檢索。
Humanity ’ s Last Exam:
由 Scale AI 和 Center for AI Safety(CAIS)聯(lián)合發(fā)布的一項難度極高的基準測試,涵蓋科學、技術、工程、數(shù)學甚至是人文藝術等多個領域。題目大多為開放式,不僅需要 AI 進行多個步驟的復雜推理,還需要 AI 發(fā)揮一定的創(chuàng)造性。這項測試能夠有效評估 AI 是否具備跨學科的綜合問題解決能力。
(2)編程領域
LiveCodeBench:
這是一項貼近現(xiàn)實的編程能力測試。與傳統(tǒng)的編程測試只關注代碼的正確性不同,AI 會被置于一個 " 實時 " 的編程環(huán)境中,并根據(jù)問題描述和一組公開的測試用例編寫代碼,而代碼將會使用一組更復雜的隱藏測試用例運行并評分。這項測試主要考驗 AI 編程是否具備較高的魯棒性以及處理邊界情況的能力。
SciCode:
這一項編程測試則更偏向于學術性,專注于科學計算和編程。AI 需要理解復雜的科學問題并用代碼實現(xiàn)相應的算法或模擬。除了考驗編程技巧,還需要 AI 對科學原理具備一定深度的理解。
(3)數(shù)學領域
AIME:
全稱 American Invitational Mathematics Examination
美國高中生數(shù)學競賽體系中的一環(huán),難度介于 AMC(美國數(shù)學競賽)和 USAMO(美國數(shù)學奧林匹克)之間。其題目具備較高的挑戰(zhàn)性,需要 AI 具備創(chuàng)造性的解題思路和數(shù)學功底,能夠衡量 AI 在高級數(shù)學領域中的推理能力。
MATH-500:
從大型數(shù)學問題數(shù)據(jù)集 "MATH" 中隨機抽取 500 道題構成的測試,覆蓋從初中到高中競賽水平的各類數(shù)學題目,涵蓋代數(shù)、幾何和數(shù)論等領域。題目以 LaTeX 格式給出,模型不僅要給出答案,還需要有詳細的解題步驟,是評估 AI 形式化數(shù)學推理和解題能力的重要標準。
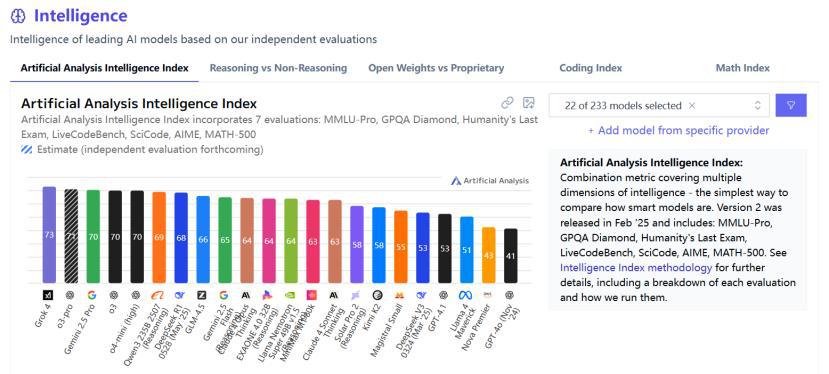
圖:Artificial Analysis 的 AI 模型智能排行榜
不過,由于模型的用處不同,各大平臺并不會采用相同的測評標準。
例如,司南(OpenCompass)的大語言模型榜單根據(jù)其自有的閉源評測數(shù)據(jù)集(CompassBench)進行評測,我們無法得知具體測試規(guī)則,但該團隊面向社區(qū)提供了公開的驗證集,每隔 3 個月更新評測題目。
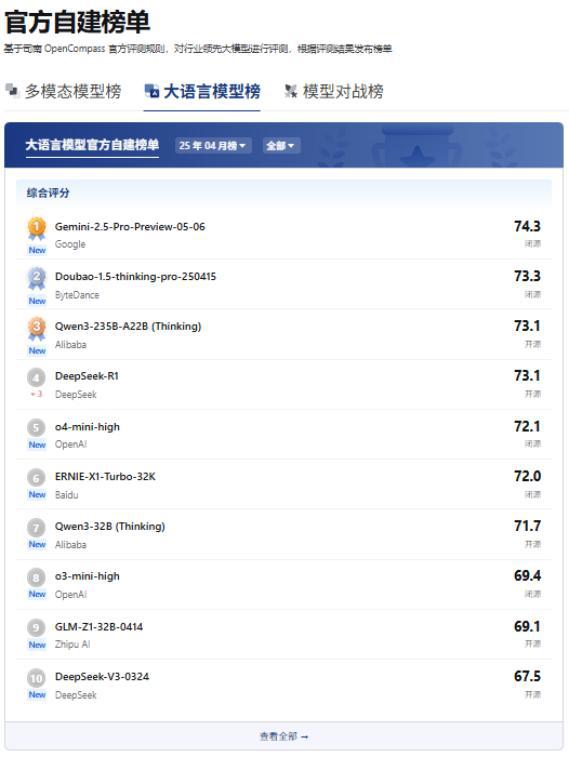
圖:OpenCompass 大語言模型榜
與此同時,該網(wǎng)站也選取了一些合作伙伴的評測集,針對 AI 模型的主流應用領域進行評測并發(fā)布了測試榜單:
 而 HuggingFace 也有類似的開源大語言模型榜單,測評標準中包含了前面提過的 MATH、GPQA 和 MMLU-Pro:
而 HuggingFace 也有類似的開源大語言模型榜單,測評標準中包含了前面提過的 MATH、GPQA 和 MMLU-Pro:
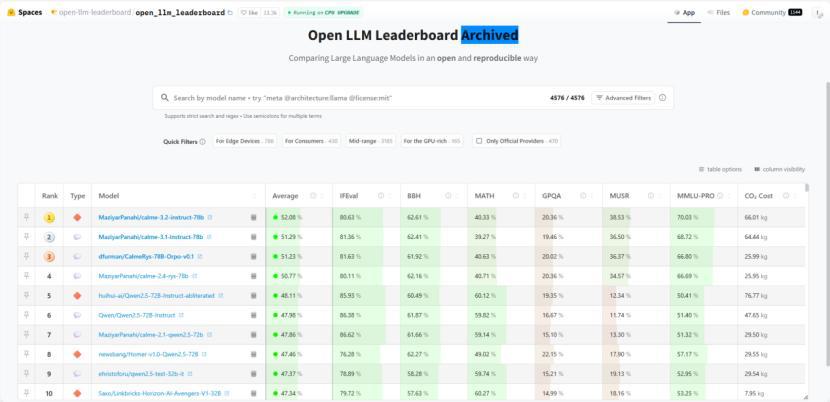
圖:HuggingFace 上的開源大語言模型排行榜
在這個榜單中,還增加了一些測評標準,并附有解釋:
IFEval:
全稱 Instruction-Following Evaluation
用于測評大語言模型遵循指令的能力,其重點在于格式化。這項測評不僅需要模型給出正確的回答,還注重于模型能否嚴格按照用戶給出的特定格式來輸出答案。
BBH:
全稱 Big Bench Hard
從 Big Bench 基準測試中篩選出的一部分較為困難的任務,構成了專門為大語言模型設計的高難度問題集合。作為一張 " 綜合試卷 ",它包含多種類型的難題,如語言理解、數(shù)學推理、常識和世界知識等方面。不過,這份試卷上只有選擇題,評分標準為準確率。
MuSR:
全稱 Multistep Soft Reasoning
用于測試 AI 模型在長篇文本中進行復雜、多步驟推理能力的評測集。其測試過程類似于人類的 " 閱讀理解 ",在閱讀文章后,需要將散落在不同地方的線索和信息點串聯(lián)起來才能得到最終結論,即 " 多步驟 " 和 " 軟推理 "。此測評同樣采用選擇題的形式,以準確率為評分標準。
CO2 Cost:
這是最有趣的一項指標,因為大部分 LLM 榜單上都不會標注二氧化碳排放量。它只代表了模型的環(huán)保性和能源效率,而無法反映其聰明程度和性能。
同樣地,在 HuggingFace 上搜索 LLM Leaderboard,也可以看到有多個領域的排行榜。
圖:HuggingFace 上的其他大語言模型排行榜
可以看到,把客觀基準測試作為 AI 的 " 高考 ",其優(yōu)點很明確:客觀、高效、可復現(xiàn)。
同時,可以快速衡量模型在某一領域或某一方面的 " 硬實力 "。
但伴隨 " 高考 " 而來的,則是應試教育固有的弊端。
模型可能在測試中受到數(shù)據(jù)污染的影響,導致分數(shù)虛高,但實際應用中卻一問三不知。
畢竟,在我們先前的大模型測評中,簡單的財務指標計算也可能出錯。
同時,客觀基準測試很難衡量模型的 " 軟實力 "。
文本上的創(chuàng)造力、答案的情商和幽默感、語言的優(yōu)美程度,這些難以量化、平時不會特意拿出來說的衡量指標,卻決定著我們使用模型的體驗。
因此,當一個模型大規(guī)模宣傳自己在某個基準測試上 " 登頂 " 時,它就成為了 " 單科狀元 ",這已經(jīng)是很了不起的成就,但離 " 全能學霸 " 還有很遠距離。
02 類型二:人類偏好競技場(Arena),匿名才藝大比拼
前面已經(jīng)說過,客觀基準測試更注重于模型的 " 硬實力 ",但它無法回答一個最實際的問題:
一個模型,到底用起來 " 爽不爽 "?
一個模型可能在 MMLU 測試中知曉天文地理,但面對簡單的文字編輯任務卻束手無策;
一個模型可能在 MATH 測試中秒解代數(shù)幾何,卻無法理解用戶話語中的一絲幽默和諷刺。
面對上述困境,來自加州大學伯克利分校等高校的研究人員組成的 LMSys.org 團隊提出了一個想法:
" 既然模型最終為人而服務,那為什么不直接讓人來評判呢?"
這一次,評判標準不再是試卷和題集,評分標準交到了用戶手中。
LMSys Chatbot Arena,一個通過 " 盲測對戰(zhàn) " 來對大語言模型進行排名的大型眾包平臺。
對戰(zhàn)時,兩個模型同時登場,并對同一個問題進行解答,由用戶決定誰輸誰贏。
用戶在投票前無法得知兩個 " 選手 " 的 " 真實身份 ",有效消除了刻板偏見。
對于一般用戶來說,LMArena 的使用方法非常簡單:
登錄 https://lmarena.ai/ 后,首先由用戶進行提問,系統(tǒng)會隨機挑選兩個不同的大語言模型,并將問題同時發(fā)送給它們。
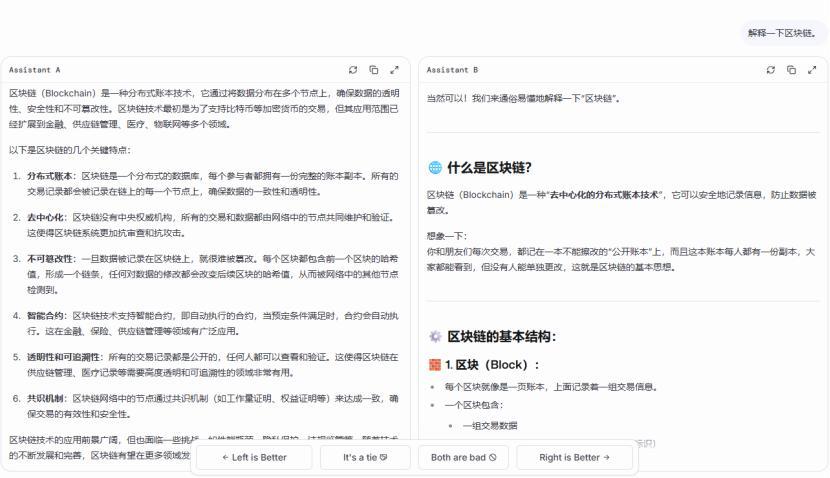 匿名標注為 Assistant A 和 Assistant B 兩個模型生成的答案會并排顯示,而用戶需要根據(jù)自己的判斷,投票選擇最合適的回答。
匿名標注為 Assistant A 和 Assistant B 兩個模型生成的答案會并排顯示,而用戶需要根據(jù)自己的判斷,投票選擇最合適的回答。
而在投票后,系統(tǒng)才會告知用戶 Assistant A 和 Assistant B 分別是哪個模型,而這次投票也會加入到全球用戶的投票數(shù)據(jù)中。
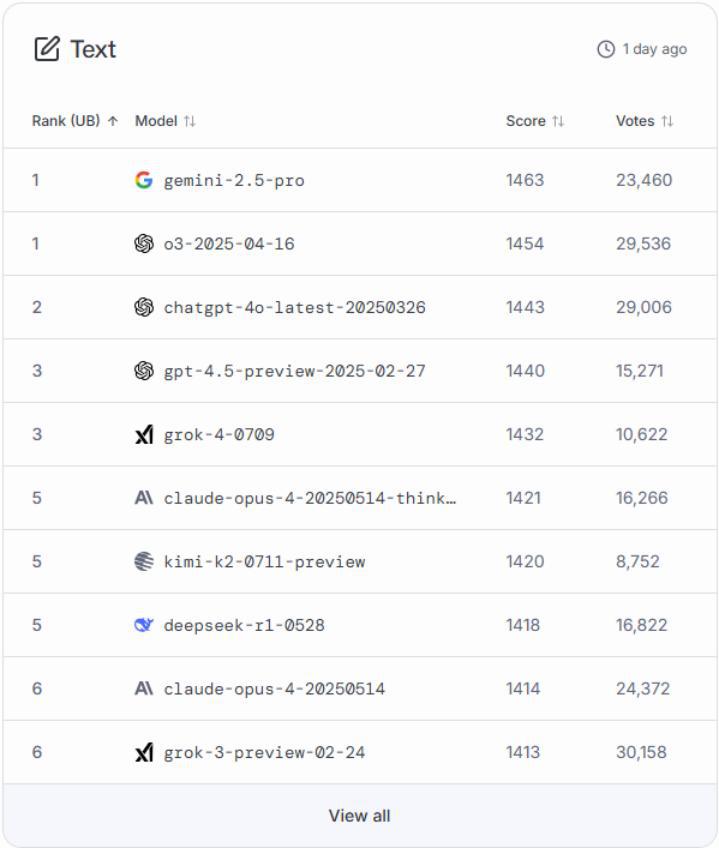
圖:LMArena 文本能力排行榜
LMArena 中設計了七個分類的排行榜,分別是 Text(文本 / 語言能力)、WebDev(Web 開發(fā))、Vision(視覺 / 圖像理解)、Text-to-Image(文生圖)、Image Edit(圖像編輯)、Search(搜索 / 聯(lián)網(wǎng)能力)和 Copilot(智能助力 / 代理能力)。
每個榜單都是由用戶的投票產(chǎn)生的,而 LMArena 采用的核心創(chuàng)新機制就是 Elo 評級系統(tǒng)。
這套系統(tǒng)最初用于國際象棋等雙人對戰(zhàn)游戲,可用于衡量選手的相對實力。
而在大模型排行榜中,每個模型都會有一個初始分數(shù),即 Elo 分。
當模型 A 在一場對決中戰(zhàn)勝模型 B 時,模型 A 就可以從模型 B 那贏得一些分數(shù)。
而贏得多少分數(shù),取決于對手有多少實力。如果擊敗了分數(shù)遠高于自己的模型,則會獲得大量分數(shù);如果只是擊敗了分數(shù)遠低于自己的模型,則只能獲得少量分數(shù)。
因此,一旦輸給弱者,則會丟掉大量分數(shù)。
這個系統(tǒng)很適合處理大量的 "1v1" 成對比較數(shù)據(jù),能夠判斷相對強弱而非絕對強弱,并能夠使排行榜動態(tài)更新,更具備可信度。
盡管有相關研究人員指出 LMArena 的排行榜存在私測特權、采樣不公等問題,但它仍是目前衡量大語言模型綜合實力較為權威的排行榜之一。
在 AI 新聞滿天飛的環(huán)境下,它的優(yōu)勢在于消除用戶先入為主的偏見。
同時,我們前面提到的創(chuàng)造力、幽默感、語氣和寫作風格等難以量化的指標將在投票中得以體現(xiàn),有助于衡量主觀質量。
但是,簡單的流程和直觀的 " 二選一 " 也為類似的競技場平臺帶來了不少局限性:
一是聚焦于單輪對話:其評測主要采取 " 一問一答 " 的方式,而對于需要多輪對話的任務則難以充分進行評估;
二是存在投票者偏差:這是統(tǒng)計中難以避免的現(xiàn)象,投票的用戶群體可能更偏向于技術愛好者,其問題類型和評判標準必然無法覆蓋普通用戶;
三是主觀性過強:用戶對于 " 好 " 和 " 壞 " 的評判過于主觀,而 Elo 分數(shù)則只是體現(xiàn)主觀偏好的平均結果;
四是缺失事實核查性:用戶在對兩個模型進行評判時,注意力往往放在答案的表述上,而忽視了回答內容的真實性。
03 我們到底該看哪個排行榜?
AI 江湖的 " 武林大會 " 遠不止我們提到的這些排行榜。隨著 AI 領域規(guī)模的不斷擴大,評測的戰(zhàn)場本身也變得越來越復雜和多元化。
很多學術機構或大型 AI 公司會發(fā)布自家的評測報告或自建榜單,體現(xiàn)出技術自信,但作為用戶,則需要 " 打個問號 "。
就像足球比賽有主客場之分,機構也可以巧妙地設計評測的維度和題目,使其恰好能放大某些模型的優(yōu)勢,同時規(guī)避其弱點。
另一個更加宏大的趨勢是,大模型的評測榜單正在從 " 大一統(tǒng) " 走向 " 精細化 "。
據(jù)不完全統(tǒng)計,迄今為止,全球已發(fā)布大模型總數(shù)達到 3755 個。
" 千模大戰(zhàn) " 的時代,一份冗長的通用榜單,顯然無法滿足所有人的需求。
因此,評測的趨勢也不可避免地走向細分化和垂直化。
那么回到最初的核心問題:到底誰更權威?
觀點很明確:沒有任何一個單一的排行榜是絕對權威的。
排行榜終究是參考,甚至不客氣的說,"AI 競技場 " 歸根到底只是一門生意。對于高頻刷榜的模型,我們務必要警惕——不是估值需求驅動,便是 PR 導向驅動。是騾子是馬,終究不是一個競技場能蓋棺定論的。
但對于普通用戶來說,評判一個模型的最終標準是唯一的:它是否真正對你有用。
評價和選擇模型,要先看應用場景。
如果你是程序員,就去試試 AI 編寫代碼、檢查和修復 Bug 的能力;
如果你是大學生,就讓 AI 去做文獻綜述,解釋學術名詞和概念;
如果你是營銷人,就看看 AI 能否寫出精彩的文案、構思和創(chuàng)意。
別讓 " 登頂 " 的喧囂干擾了你的判斷。
大模型是工具,不是神。看懂排行榜,是為了更好地選擇工具。
與其迷信排行榜,真如把實際問題交給它試一試,哪個模型能最高效優(yōu)質地解決問題,它就是你的 " 私人冠軍 "。
來源:錦緞















